Almost every technological leap I’ve ever taken has been preceded by something Jon Udell articulated before I got there. Today is no exception:
“I dislike the phrase “human in the loop” because it cedes authority to the machines. Let’s flip the narrative. It’s our loop, we work the same way we always have, now we recruit agents to join the team. An agent-assisted process need not be a black box that takes in prompts and emits features.”
It’s not just the idea of the shared experience with the loop or the concept of “visible workings”, it’s also the idea that we’re “recruiting agents to join the team”.
After proving out some ideas (see more here, here, here and here) around using GitHub as the shared workspace for building software with agents and managing my AI team, I’ve extracted and published the configuration as a re-usable framework. It’s called Open AgentOS:
https://github.com/open-agentos/spec
Why create a spec for an open agent OS?
The software development that I enjoy most is when it’s a team sport. Solopreneuring is certainly exciting, too, but there’s nothing quite like leaning into a challenge with the people you trust and depend on every day, everyone knowing their role, fitting each other’s work together, and coming out the other side with something only you and your team could’ve done.
Agents are becoming part of that dynamic, but it can create some friction. To carry on with the team sport analogy, you wouldn’t want to have a super talented member of the team skipping all the training sessions and team meetings. That player may help you score more points when they show up to the game, but the achievement is hollow and temporary, not a systemic change that builds a high functioning team that wins consistently.
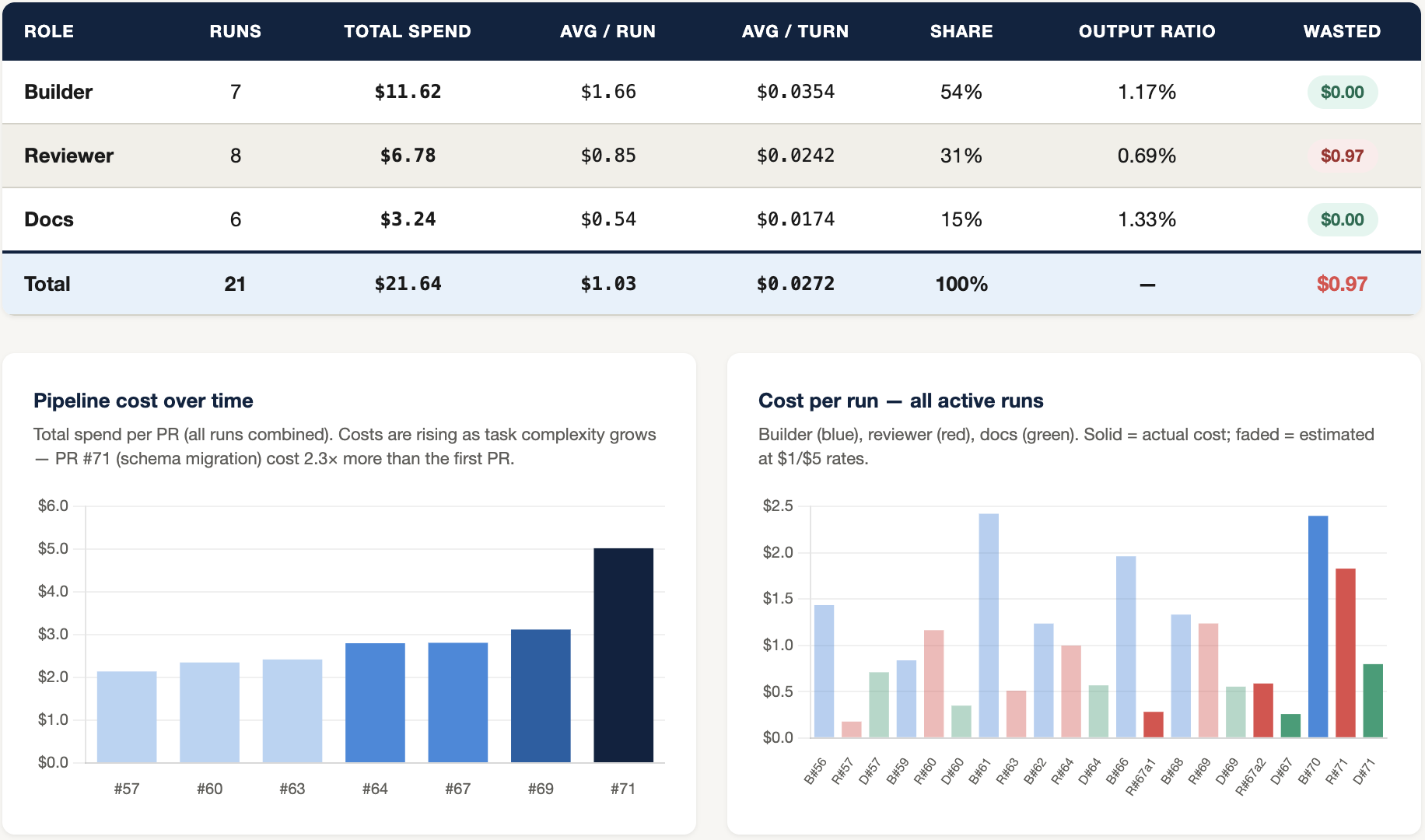
I want to know what my AI agents are doing and how they’re doing it. I want to see where problems might be forming in the system, what costs are accumulating, and where improvements can be made. It’s not hard to instrument current systems such as GitHub to report out the data that will show you what’s working and what’s not. It takes a few minutes to configure.
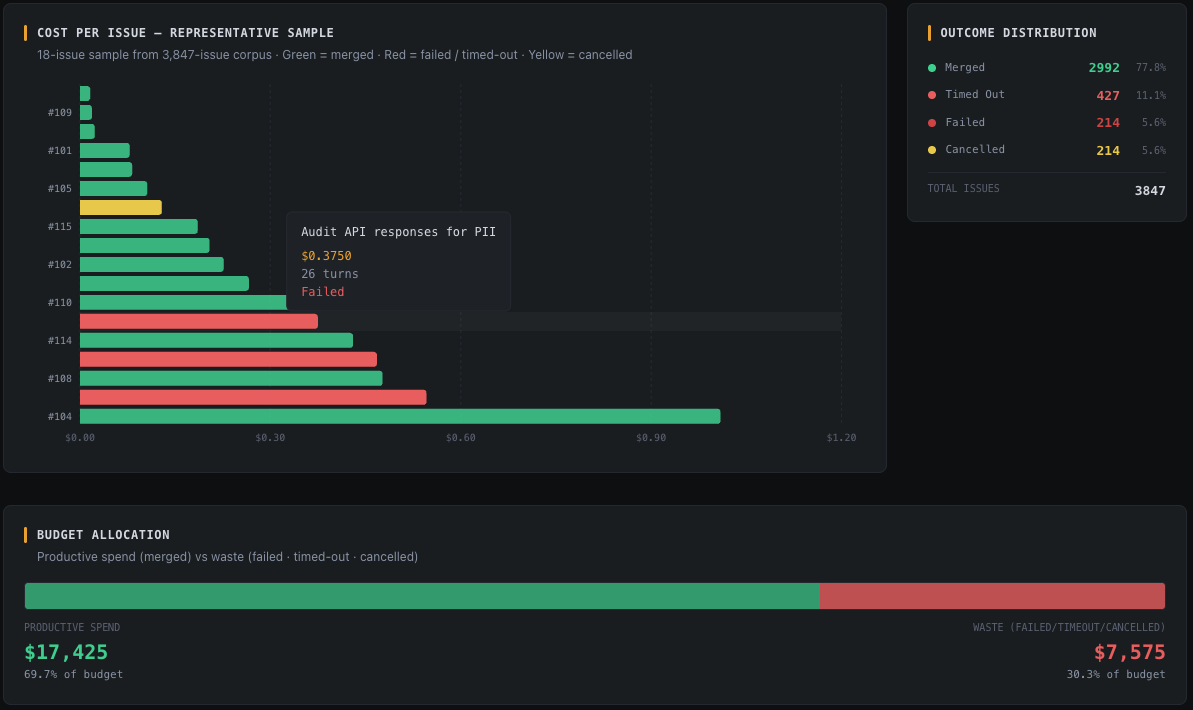
Once it’s setup the experience is a lot more like working with a team. You can think about what tools you want to recruit into your environment and integrate them without having to buy a whole new product or signup for a new service. It should just work the same way you’ve been working for the last several years. …but with some new players on your team.
The spec covers how Open AgentOS works in detail. In short, GitHub acts as an agent operating system. Issues are used to manage state and trigger different agents to contribute when called upon. You can look across your team of agents and their work using the Projects feature. And everything outputs raw receipts and detailed event data that you can use for analysis.
The system is designed with a few principles in mind around observability and agent accountability, and it is extensible so that you can bring your own agent and add your own plugins. It’s intended to operate with any stack so you can make it work however, wherever you want.
Anyone interested in joining the team here is more than welcome to contribute. I’d love to see some new capabilities around dashboards, non-github environments where this could also work, and plugins for other use cases and integrations.