GitHub-as-AgentOS opens a whole suite of analytics options that make it possible to steer the ship instead of just closing your eyes and hoping for the right outcome. By adding some event logging to the agents’ activities simple dashboards can be build for tracking things like cost per turn per agent, context inflation, pipeline cost over time, etc.
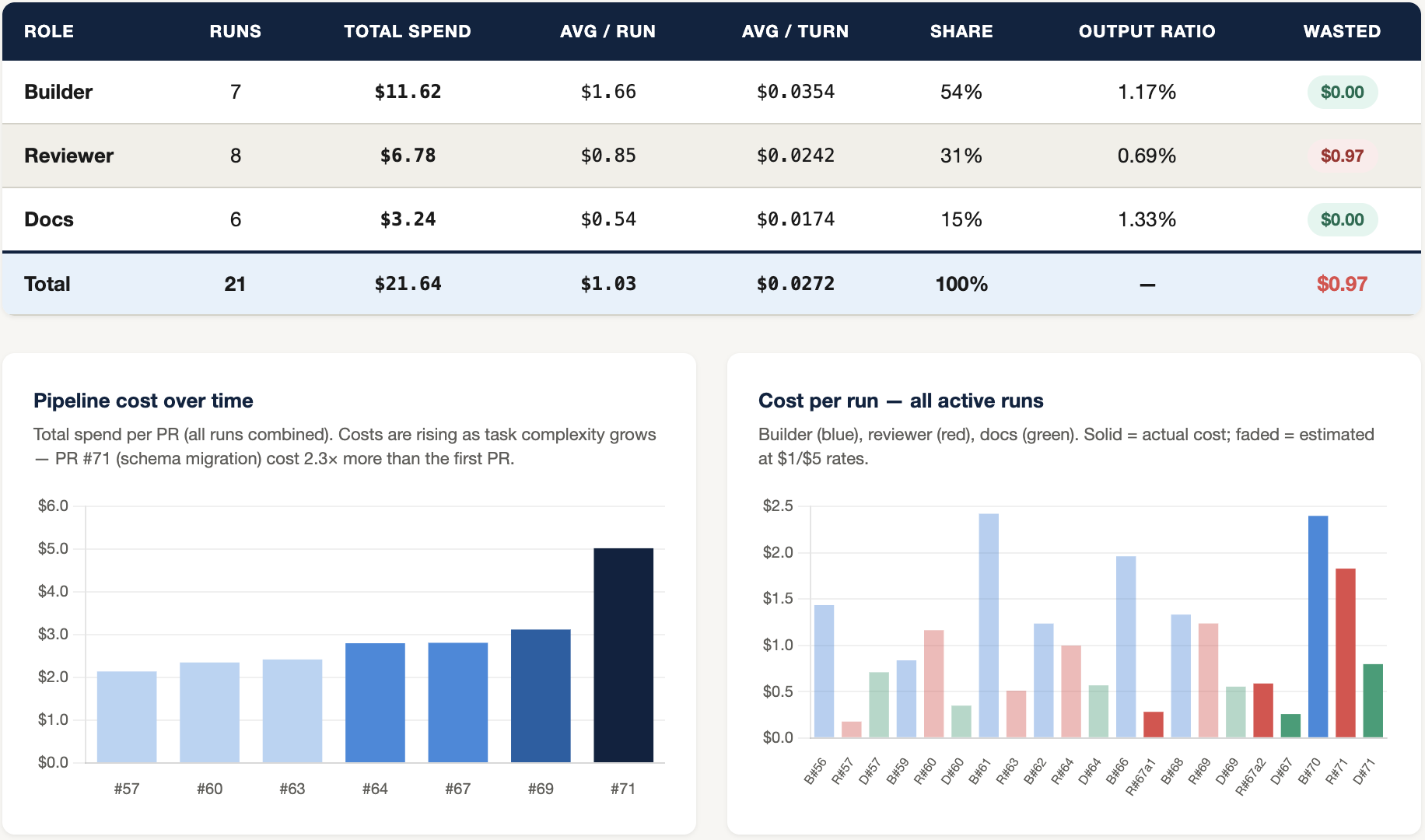
In my case, the dashboard pointed to a problem in the pipeline that no code review would’ve found.
The reviewer agent was doing it’s thing, running through acceptance criteria, which is what it’s supposed to do, but the chart showed outsized token consumption vs what I would expect of it. The whole idea of the reviewer agent is that it shouldn’t need a huge amount of context to verify a file has changed as expected or that a script’s output is valid.
I can also see what I don’t know.
My reviewer is simply approving code or sending it back with change requests. I don’t know whether the quality of the code is good or whether the solution is sensible. Introducing some scoring and qualitative rubrics for my reviewer agent to use would give me a sense of how effective my builder agent is at solving certain problems. It could give me a sense of which LLMs are better for which types of challenges. In the future, it might be smart to introduce multiple builder agents per run. Then their solutions could be compared and graded before choosing which to merge down, feeding that knowledge back into the system so it learns.
The insights are helping me to prioritize optimizations.
The dashboard shows that context inflates more than 10x from the first turn to the last, and the problem is getting worse with each new issue. Digging into it further I can see that introducing compaction steps in the builder agent’s workflow could drop my costs for that agent by an estimated 30%, maybe more.
I might also introduce an escalation moment in any run that exceeds $2. When it hits the $2 threshold then it could stop and ping me for approval.
There’s more work to do around running multiple issues simultaneously and adding more specialized agents with different properties in addition to the optimizations made obvious by the event traces. But the system is demonstrating that we can know what our agents are doing and improve them in measurable ways.
Leave a Reply